大家好,我是Chunel,一个不会写代码的纯序员。今天,我想跟大家聊聊,我在Caiss中,加入了哪些工程化技术,从而完成功能的扩展和性能的优化的吧。
在聊之前,先显示的附上传送门:Caiss源码 Github链接
| 高并发 |
多线程编程
Caiss中加入了两种多线程技术,分别是同步和异步调用(对应的是代码中manageCtrl中内容)。
其中,同步并发主要是针对调用层开辟多线程的情况,使得上层可以在不同的线程中,使用Caiss分发的不同句柄调用同一个底层Caiss模型进行搜索计算。异步并发主要是针对调用层仅开辟一个线程,并且无法阻塞的情况,通过在Caiss框架内部开辟线程池的方法,依次执行上层的调用方法。
同步并发的用户,可以通过GetResult方法获取最后的计算结果。而异步并发的用户,可以通过传入回调函数方式,获取最终结果信息并进行进一步处理。
并行计算
Caiss在处理过程中,有大量的计算过程。比如,在内部子优化模型准确率的时候,为了得到真实准确的查询结果,会有大量的暴力计算过程,这一部分整体是比较耗时,而且循环逻辑很难通过自己开辟线程来处理。
在这里,Caiss内部引入了OpenMP方法。通过在循环中自行开辟线程计算的方式,既确保了计算的准确性,又提高了并发性,从而节省了大量的计算耗时。
读写锁
Caiss在底层实现多线程和线程池功能,是通过读写锁在保证线程相互独立的(对应threadCtrl中内容)。Caiss的主要功能是相似查询,查询任务较多,同时也支持了实时的增删改功能。在查询的时候加入读锁,因为对数据和模型无改动,多线程并发不会影响运行结果;在增删改这些对数据和模型有改动的任务中加入写锁,保证了最终结果的互斥正确性。
相比于传统的互斥锁或临界区技术,保证了不同线程查询结果相互独立但查询流程不互斥,减少了线程同步的等待时间,从而极大的增加了并发查询性能(图文无关)。

与Java中提供了官方的线程池和各种锁不同,纯CPP在多线程功能方面明显有所欠缺。为了减少对第三库的依赖,以上这些功能都是纯序员纯手写完成。
必须承认,自己实现的功能并没有Java官方提供的强大(哎,谁让咱是写C++的呢),但也从实现的过程中学到一些东西。
特别是在做异步并发多线程互斥的过程中,遇到了各种不好复现的问题,而且又没测试人员帮我测试。那个时候,基本上每个周末都晚上都不睡觉的,就为了修复bug。好在这些问题都一一解决了,最终的结果是,Caiss在同步和异步并发的模式下,均4线程运行12+小时无异常。
| SQL化 |
跟市面上其他服务化框架不同,Caiss的定位是一个加速相似计算引擎,而非强服务化的后端组件。说具体一些,主要应该是对应对外暴露的查询服务和纯研究性算法中间的一层。当然,算法优化和服务提供,在Caiss中也均有体现。
Caiss在v2.0.1版本中,正式加入了SQL化的功能(对应sqlCtrl中内容)。通过ExecuteSQL方法,传入类似如下的SQL查询串,即可实现CRUD的功能。
* SELECT * FROM Model_A WHERE word LIKE 'water' limit 5
* INSERT INTO Model_B(key1, key2) VALUES(" + value1 + "," + value2 + ")
* DELETE FROM Model_C WHERE word = 'water'
之所以做这个功能,主要灵感来自于平日工作的时候,接触到的跟数据查询相关的框架和平台都支持了SQL语法。不要误以为我们只是在关注几捆白菜、几斤水果的流量,我们的工程技术团队也是有星辰大海的,哈哈。
这个功能,在我接触的其他ANN框架和服务中,从未见过。主要优势就是可以通过一个函数实现Caiss提供的基本所有功能,而且SQL语句也是基本上所有程序员都能读懂的内容,没有什么门槛。这算是Caiss的一处独家功能吧,大家可以来试试看哈。
| 多语言 |
为了方便更多的人更方便的用起来,纯序员在Caiss中提供了多语言版本,比如Python,Java,C#。当然了,具体的实现方法,都是采用上层胶水的方法,去封装C版本的Caiss动态库。具体说来,Python对应的是ctypes;Java对应的是JNA;C#对应的是DllImport。这些在Caiss工程中都提供了可以正常work的源码,大家也可以根据自己的业务调用流程,做针对性修改。
以上这几种语言都是纯序员在工作中用过的,多多少少会写一些。其他的,比如go,swift等语言的版本,也有朋友在开发中,敬请期待。也欢迎各位大佬的随时加入和贡献。
| 批量查询和缓存 |
批量查询
传统的ANN算法,是提供单向量查询相似的topK个向量的功能。考虑到多次调用过程(特别是服务调用的情况),有一部分性能是消耗在调用的流程中,Caiss在内部加入了批量查询的功能。比如,传入查询单词是"hello|world"的时候,会返回"hello"和"world"两个词语对应的相似内容。
这个功能乍一看就是写个for循环的事情(实际上也的确是),但是由于我早期做的时候,并没有想过做批量查询,更没有考虑到内部缓存的格式和最终结果的格式对这一块的影响,导致了在做这个功能的时候,工程的很多地方都需要改动。
这个功能做了挺长时间的,而且整个输出结果的JSON格式也跟着做了改动。不过好在现在也都正常work起来了,就算是为自己在设计方面知识和意识的欠缺买单吧。
缓存机制
Caiss在做词语查询的时候,会先经过一层在线缓存层,缓存里会记录最近查询的N次查询结果。如果一个词语近期被查询过,在接下来的查询中会直接从缓存中找到对应的结果,省略了在模型中查询和后期处理的流程,从而极大的降低了查询耗时。
在做缓存功能的时候,主要是使用LRU机制。而且我们是考虑到同一个词语被多次查询,但是查询的topK值不同;或者多次查询过程中,词语对应的信息被修改或者删除等情况的,大家可以放心使用。
个人觉得做的不太好的是,Caiss没有对外暴露缓存相关的设定参数,而且也没有加入类似缓存定时自动过期的功能。这些看今后有时间的话再优化一波,大家也多给提提宝贵意见哈。
| 结束语 |
以上这些介绍的,主要是Caiss在算法工程化方面做的一些事情。下一章,纯序员打算跟大家聊一聊关于Caiss在服务化、版本控制和用户交互方面做的一些内容。这一部分,其实是纯序员比较薄弱的部分,感觉做的也比较简单。但作为Caiss整体架构中跟用户最接近的一个部分,我认为还是有必要跟大家聊一聊的。
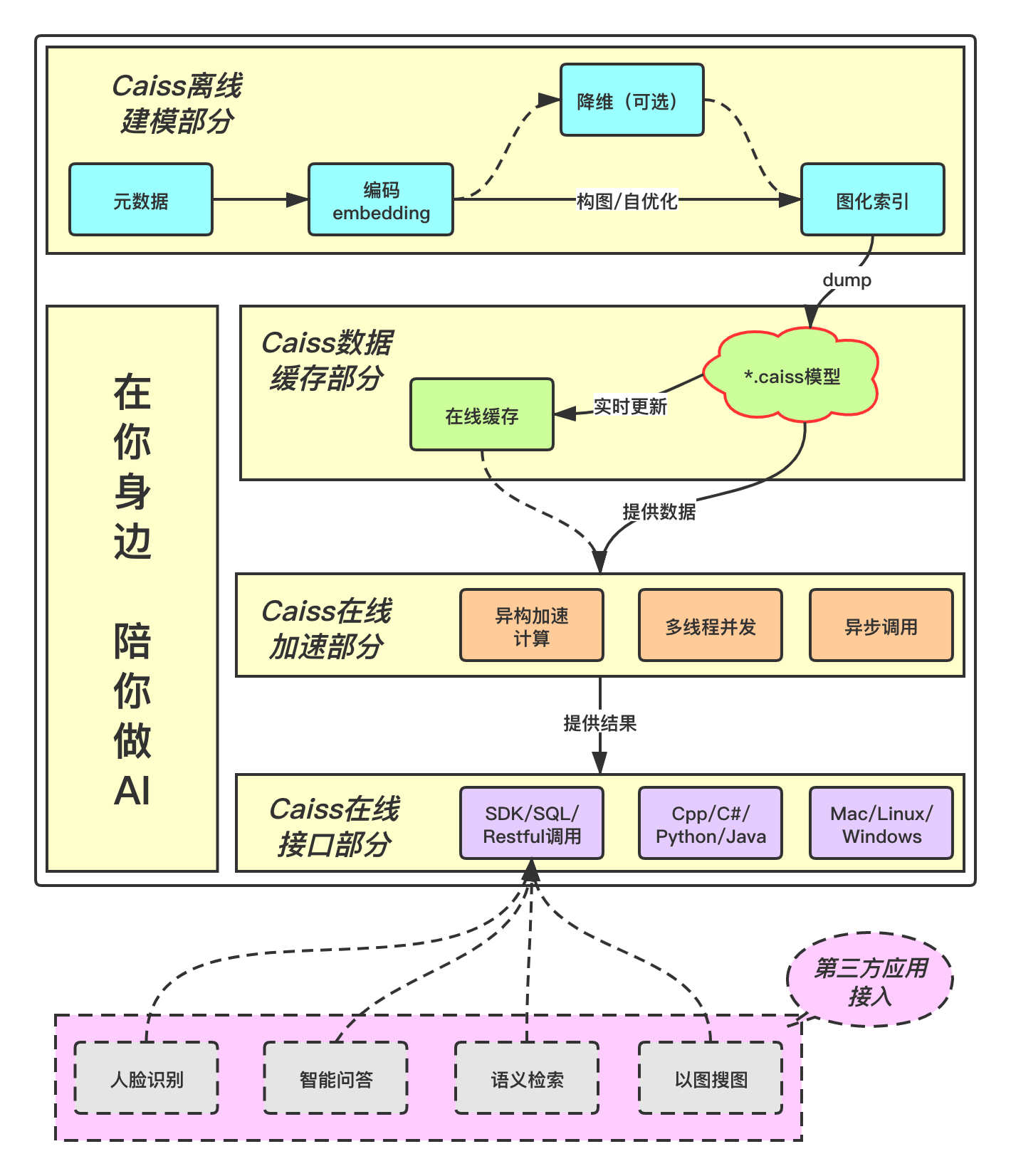
当然,这并不是全部。具体的内容,大家可以通过源码或者架构图来进一步了解。也欢迎大家随时联系我们,和我们讨论,并给我们提出宝贵的意见。
新的一年又要来了,时间好快啊。纯序员祝福大家在新的一年,都有新气象吧。
[2020.12.26 by Chunel]
个人信息
微信: ChunelFeng
邮箱: chunel@foxmail.com
个人网站:www.chunel.cn
github地址: https://github.com/ChunelFeng