大家好,我是不会写代码的程序员 Chunel,很高兴在这里跟大家见面了。
前阵子,我们发布了 并行调度框架 CGraph 和 taskflow 性能对比实测 视频,验证了在各种常见情况下,色图的劲爆性能。让我们意识到,色图已经进入了领域的无人区。如果之前我们要做的,是更好的学习和借鉴别人的优点的话,那今后更重要的是不断的找到自身的缺点和不足,提升自己的同时,也可以反哺别人了。
本文主要介绍,在这个 8乘8的全连接性能测试用例中,test-performance-04.cpp ,我们从 v2.6.0版本的 11.5s,优化到当前的7.2s过程中,做了哪些改进吧。
首先,还是先上代码:https://github.com/ChunelFeng/CGraph
| 优化并发逻辑 |
我们知道,将逻辑放到多个线程中执行,而不是串行,可以有效的提升性能。色图也正是为这件事情应运而生的,但需要面对一个问题:如何更好的设计并发逻辑,尽可能的将可以并行的逻辑并发,减少串行依赖的消耗。
在老版本(今后通指v2.6.0版本)中,有这样的设计:在每次 pipeline->run() 函数运行开始的时候,先依次重置每个 element 的依赖信息,如下图:
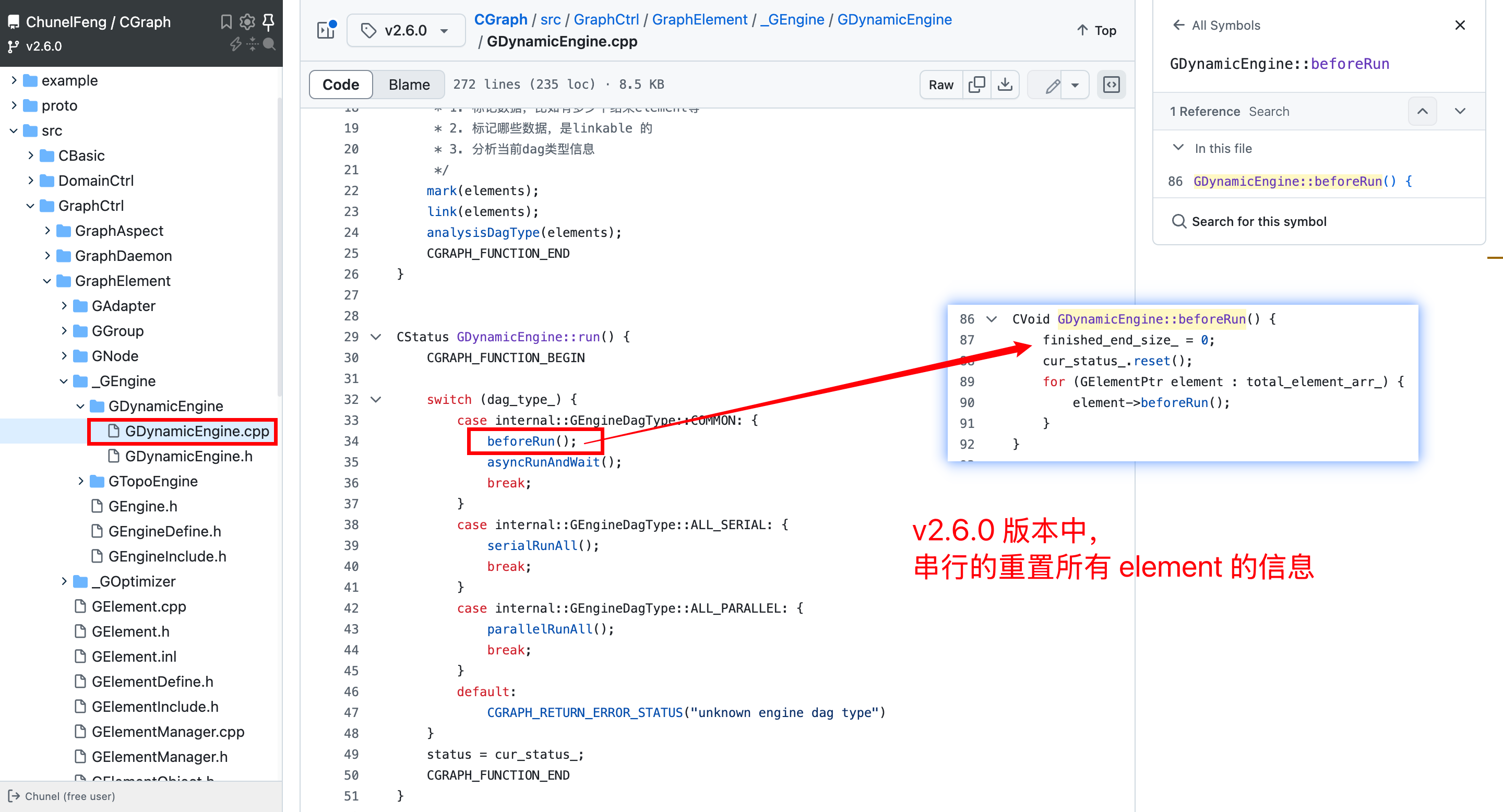
这个执行逻辑,在普通的 pipeline中,耗时基本可以忽略不计,因为重置 element 的函数耗时非常少。但是,在这个测例中有64个element,也就是这个重置逻辑,需要串行64次。特别是由于测试的element逻辑,都是 i++ 这种情况,这个处理的耗时就很热点了。热点到 如果我们使用 perf top 去查看的话,会发现 beforeRun() 这个函数的耗时,居然是整个流程中最多的。
我们来分析一下这个问题。首先,element是根据依赖逻辑执行的,或并行或串行。是不是可以把重置逻辑,放到每个 element 具体执行之前(或之后)就可以了。这样的话,既能保证每次执行完成信息被恢复,从而下次执行的时候,逻辑也是正常的;又能保证不需要依次执行 beforeRun(),减少了串行的开销。
还有一点,我们想,这个8x8 的逻辑中,最前面的 8个element,实际上是没有任何依赖逻辑的。也就是说,这8次 beforeRun() 执行,实际上是冗余的。
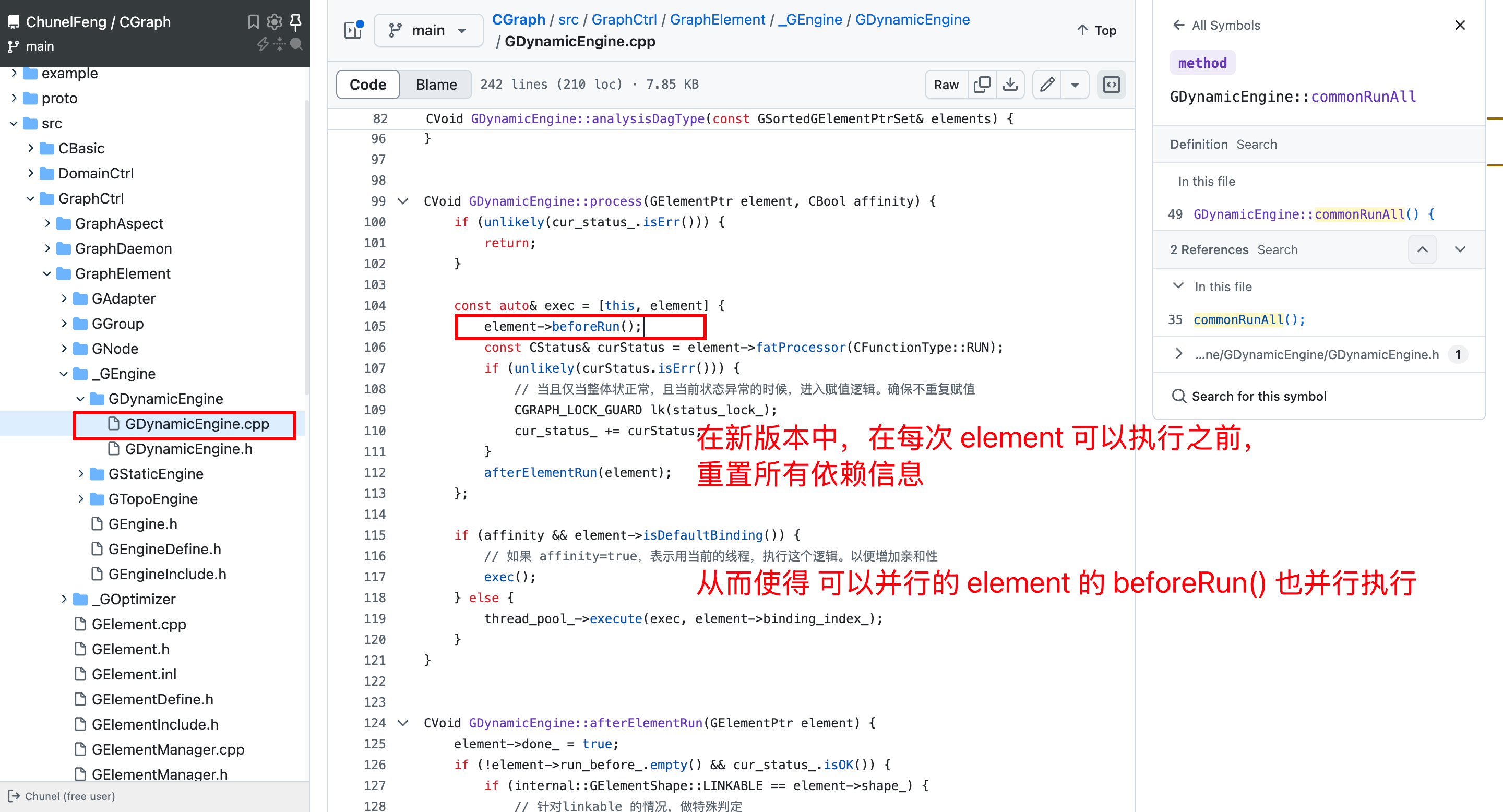
我们来按照每次执行 beforeRun() 为1ms来计算,最初的串行版本是64ms。而最新的版本中,首先,减少了第一列的8个 element的8次计算,后面的7列(每列8个并发element)中,在最极限的理论下,是可以每列都并行的,也就是一共 7ms。
btw:最新版本中,element的 beforeRun() 方法,改名为 refresh() 了。内容不变
| 精简无用定义 |
我们知道,定义一个变量耗时是很少的。但是,在一些极限性能情况下(哈哈,我说的就是进入无人区之后),就是一件需要考量的事情了。比如,常见的 std::function<> 和 lambda表达式 功能基本一样,但是前者的耗时远高于后者。
我们在做火焰图观测的时候,我们发现 v2.6.0版本中,生成和销毁 std::package_task 的过程中,实际上也是有一定的耗时的。

项目刚开始使用 std::package_task 来包装任务,主要是由于静态引擎的执行过程中,需要获取element执行的 返回值信息。但这个设定,动态引擎正好不需要。于是,我们直接提供了新的 threadpool::execute() 接口,功能一样,只是不在通过 package_task 向上游返回运行结果值。

可以很明显的看出来,这样一来不仅减少了 std::package_task 的构造销毁耗时,整体的执行性能也上来了。原先版本中,std::package_task::operator() 占整体耗时的 29%,现在红框中的逻辑,仅占17%,而这两个地方的功能,对于动态执行是完全一样的。
| 平替动态转换 |
我们知道,如果想尝试将 Base* 转义成 Devide* 的话,需要用到 dynamic_cast 这个方法。色图中,在获取 GParam参数的时候,有必须通过 Base* -> Devide * 的方式,来获取执行类型的指针,还需要再类型不匹配的情况下,返回 nullptr,所以用到了 dynamic_cast。但这个方法本身,是有较多的消耗的。这在CGraph这种基础组件中,是要尽可能避免的。
Base* b = new Devide();
Devide* d = dynamic_cast<Devide *>(b);
在新版本中,我们修改了 这一块的实现。通过 typeinfo 来判断,传入的 type 和 对应的GParam的 type是否匹配,如果匹配的话,通过 static_cast 来转就好了。不匹配的话,返回 nullptr,跟之前逻辑保持完全一致。
Base* b = new Devide();
Devide* d = (typeid(Devide) == typeid(*b)) ? static_cast<Devide *>(b) : nullptr;
我们在 Linux 环境上实测了一下,新版本的耗时,仅有 dynamic_cast 强转的 30%左右。主要原因,就是没有了 dynamic_cast 逻辑中,最耗时的那个函数调用。
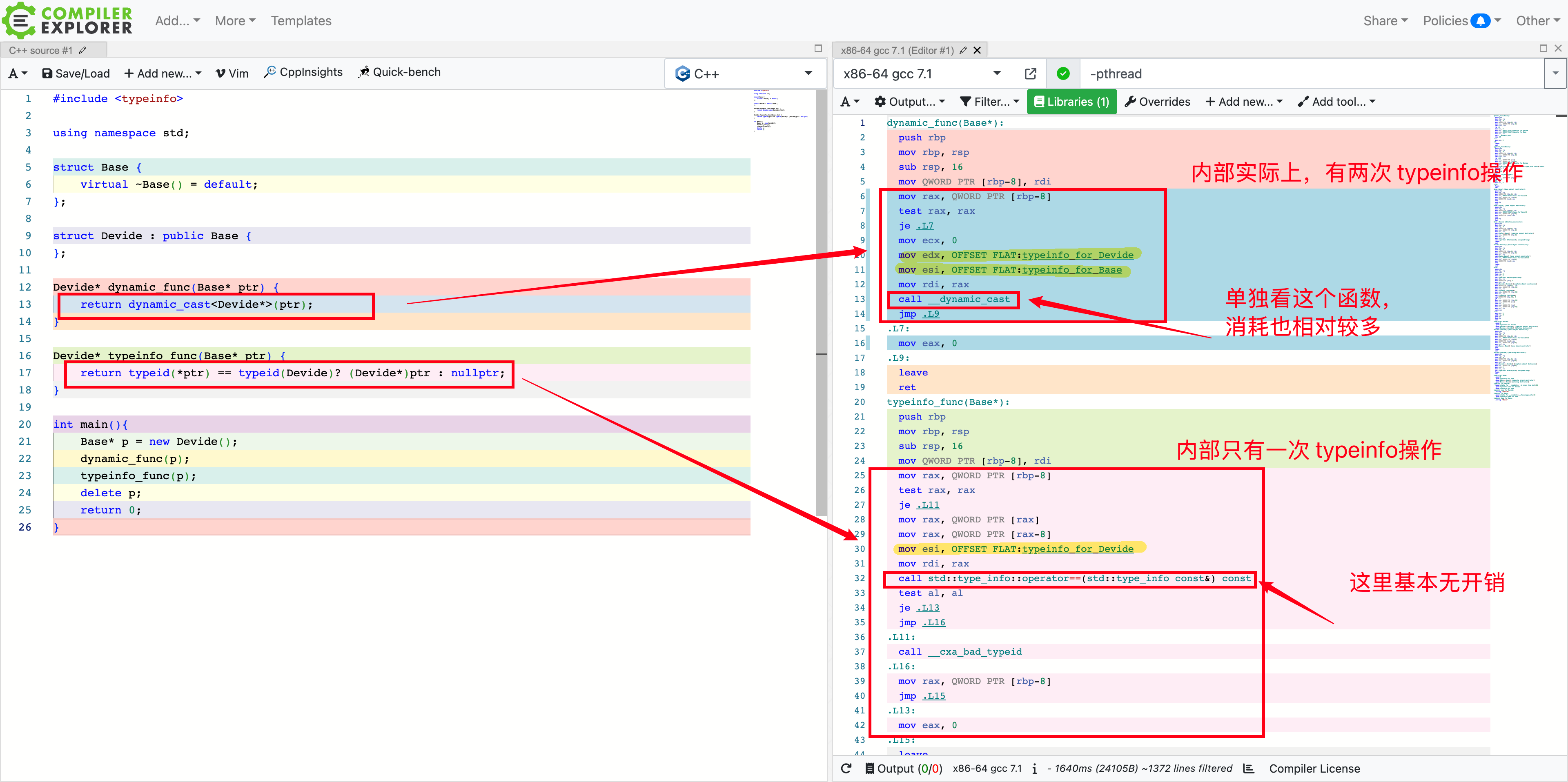
这里也想引申出另外一个话题,新版本可以在所有的场景下,完全平替 dynamic_cast 么?有对这一块比较理解的小伙伴,欢迎指教。
| 写在最后 |
这篇文章选取的几个点,更多的都是我们在跟过去的自己做对比。长期开发和维护色丶图的经历,让我会更有意识的去关注一点非常细小的可能产生问题的点。
最近在工作中,也经常要处理一些性能问题。项目和系统复杂度上去之后,问题的定位就变得更加困难和棘手。特别是对于一些低概率偶现的热点问题,往往需要各种工具、各种知识杂交起来,好几个团队联手埋头苦看,才能最终分析定位和解决。在这种情况下,将尽可能多的信息 有规律的组织起来、可视化、可解释性 就变得非常重要。有好用的工具,总结形成有理论支撑的、可复用的经验思路,可能会让我们在这个领域走的更稳更久一些。
总结一下这篇文章介绍的功能中,我们用到的工具:
- godbolt:用于查看不同实现对应的汇编结果
- uftrace:用于查看系统函数中的耗时分布
- perf:用于发现进程的热点函数,主要用到 perf top 功能
- 火焰图:查看进程中每个部分的耗时情况
- benchmark:用于dynamic_cast 改进前后的性能对比
- perfetto:在查看偶现热点问题中,非常好用,推荐
我们性能优化的主题,将会一直持续下去,攒了一些比较有意义的方法,就会更新这个系列的文章。这又是一个非常大的话题,入门简单,深入很难。有兴趣的朋友,欢迎添加我个人微信,随时交流指教。小纯给你比心了哦

[2024.11.17 by Chunel]
推荐阅读
- 纯序员给你介绍图化框架的简单实现——执行逻辑
- 纯序员给你介绍图化框架的简单实现——循环逻辑
- 纯序员给你介绍图化框架的简单实现——参数传递
- 纯序员给你介绍图化框架的简单实现——条件判断
- 纯序员给你介绍图化框架的简单实现——面向切面
- 纯序员给你介绍图化框架的简单实现——函数注入
- 纯序员给你介绍图化框架的简单实现——消息机制
- 纯序员给你介绍图化框架的简单实现——事件触发
- 纯序员给你介绍图化框架的简单实现——超时机制
- 纯序员给你介绍图化框架的简单实现——线程池优化(一)
- 纯序员给你介绍图化框架的简单实现——线程池优化(二)
- 纯序员给你介绍图化框架的简单实现——线程池优化(三)
- 纯序员给你介绍图化框架的简单实现——线程池优化(四)
- 纯序员给你介绍图化框架的简单实现——线程池优化(五)
- 纯序员给你介绍图化框架的简单实现——线程池优化(六)
- 纯序员给你介绍图化框架的简单实现——性能优化(一)
- 纯序员给你介绍图化框架的简单实现——距离计算
- CGraph 主打歌——《听码农的话》
- 聊聊我写CGraph的这一年
- 从零开始主导一款收录于awesome-cpp的项目,是一种怎样的体验?
- 炸裂!CGraph性能全面超越taskflow之后,作者却说他更想…
- 以图优图:CGraph中计算dag最大并发度思路总结
- 一文带你了解练习时长两年半的CGraph
- CGraph作者想知道,您是否需要一款eDAG调度框架
- 降边增效:CGraph中冗余边剪裁思路总结
个人信息
- 微信: ChunelFeng
- 邮箱: chunel@foxmail.com
- 个人网站:www.chunel.cn
- github地址: https://github.com/ChunelFeng
