大家好,我是不会写代码的纯序员——Chunel,有一阵子没写文章了,主要是因为前阵子我把更多的精力,放到了B站的视频录制上面。也欢迎大家去B站搜索CGraph,了解相关的内容。
与此同时,我们并没有停止迭代和优化的脚步,并且在大家的帮助和建议之下,完成了不少性能点的优化。接下来,我打算分几个章节,来给大家介绍一下其中优化的思路和使用的方法。
因为内容已经涉及到一些优化选项,本篇文章默认,读者已经对CGraph有了一些了解,或者是已经使用入门了。如果还不了解相关内容的朋友,我们也推荐您阅读之前的文章,或者去B站上搜素一下相关视频集合。
按照惯例,首先上源码:

| cpu占用率 |
之前有人跟我们反馈过,在落地的过程中,哪怕是只写几个 sleep(1s)的算子,系统的cpu占用也会很高——这一定程度上阻碍的后续的落地流程。我们也注意到这个问题了,主要的原因,是我们在设计线程池的时候,为了提升并发场景性能,默认做了一些busy loop+yield的操作。
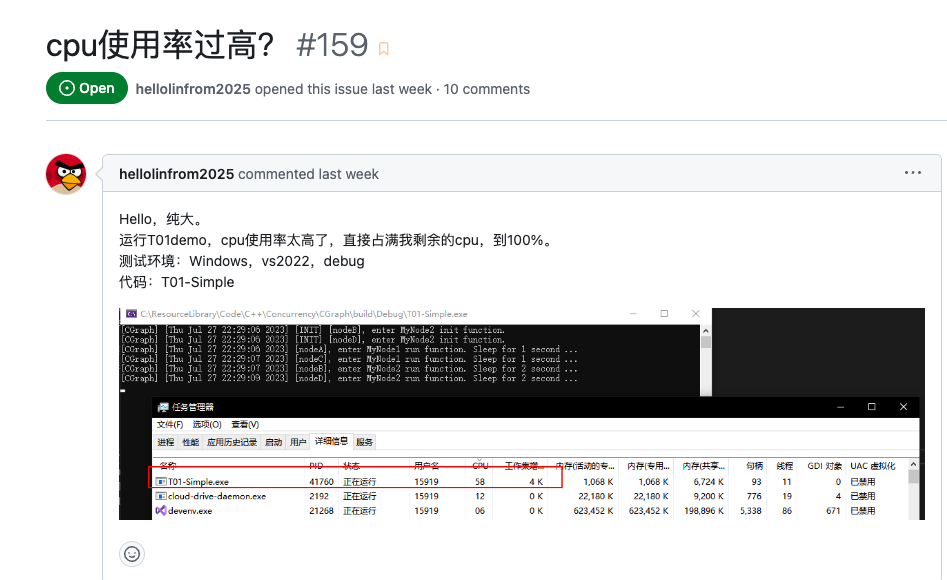
针对一些非计算密集型的pipeline,可以通过配置的方式,极大的降低系统的cpu占用率。具体的操作方式,可以参考 T01-Simple 这里的注释,只需要将主线程个数设置为0,并且设置开辟n个辅助线程执行就好了。具体执行效果,见下图:
UThreadPoolConfig config;
config.default_thread_size_ = 0;
config.secondary_thread_size_ = 8; // 需要执行的线程数
pipeline->setUniqueThreadPoolConfig(config);

原理啊,主要就是修改了辅助线程的执行逻辑。当辅助线程从 pool的queue中无法获取任务的时候,会进入 wait_for 的状态,等待再有新的任务,被push进来。当然了,我们也在这个等待上,加了一份期限(目前是 100ms)。我愿称之为:常温超导态色丶图。
整体压测下来,性能跟全部用主线程(busy loop) 的情况基本持平。在这里要解释一下,我们压测 2000w次,整体差了5s左右。这种性能的差距,在单次调度上,基本可以忽略。建议大家根据自己使用的实际情况,选择性使用更care性能的模式,还是更care cpu占用的模式——反正都是一个配置选项的问题。
特别强调一点,针对需要经常使用 yield(暂停) 和 resume(恢复)pipeline的朋友,我们强烈推荐采用全部辅助线程来执行所有的流程。可以在暂停的时候,将cpu占用率降到很低的水平。
【改动 2023.12.23】
CGraph v2.5.3 以及后期版本,降低了主线程在空闲时候的cpu占用率。用户采用默认设置(主线程)即可。
| 串行执行 |
在推广的过程中,我们也会遇到一些用户,其实本身逻辑中,就没有并发部分——比如说,一段很长的流程的算法逻辑。但是呢,又想通过算子化(或者图化),来解决原有逻辑代码逻辑混乱、难以维护的问题。
这个时候,如果选择dag执行框架,就会将原有单个线程(主线程)就可以执行完毕的逻辑,强行放到了多个线程中去执行。我们知道,多线程内部也是有损耗的。代码的结构是清晰了,但是性能却降低了。这反而违背了算法更高、更快、更强的初衷。

针对这种情况,我们提供了pipeline的串行执行功能。确保针对 a->b->c->d 的这种pipeline,运行的时候,不启动后台的线程池,而是直接通过主线程执行。在实现了算子化的同时,省掉了线程切换开销,从而兼顾了原有的性能。
又有一个问题:并不是所有的pipeline都是 a->b->c->d 这么简单的,其中还可能包含各种类型的group(特别是Condition/MultiCondition)。什么情况下,pipeline可以串行执行呢?为此,我们提供了 pipeline->makeSerial(); 方法,在pipeline构建完成之后,直接调用这个方法,如果返回值是ok的话,那就说明当前的pipeline是可以串行的。并且这个时候,色图已经为你做好了串行执行的设置。
接下来,直接运行就好了。返回值如果不是 ok的话,这个时候系统就不会做任何操作,按照原先的执行参数正常执行好了。
实验证明,在空跑大量节点的情况下,单线程串行执行的性能,比多线程好很多。推荐有类似需求的朋友,在执行之前,先 makeSerial 一下。反正返回不是ok了,也没有任何影响,对吧。
| perf功能 |
最新版本的色丶图中,我们加入了链路的perf功能,可以方便的查看整体链路上,具体哪里耗时。当然了,整体pipeline的耗时,基本上肯定都在节点内部,我们就没有标注出来调度的性能损耗。这个值通过node和node之间的时间差,也能计算出来。反正调度的损耗肯定是微秒级别的,可以忽略不计。
使用的方法,也非常简单,在pipeline构建完成之后(切记,是在pipeline构建完成,不需要init),直接调用 pipeline->perf(); 方法,就可以了。这个时候,程序会在内部自动进行埋点,并且记录和分析运行耗时。最终,以 GraphViz的格式,打印出来。在perf函数执行完毕之后,我们也会自动清除自动加入pipeline内部的埋点信息,不会有任何性能方面的影响。
您只需要将屏幕上打印出来的信息,复制到 GraphViz Online 网站,或者其他 graphviz 格式解析软件,就可以查看具体的性能分析了。如下图:
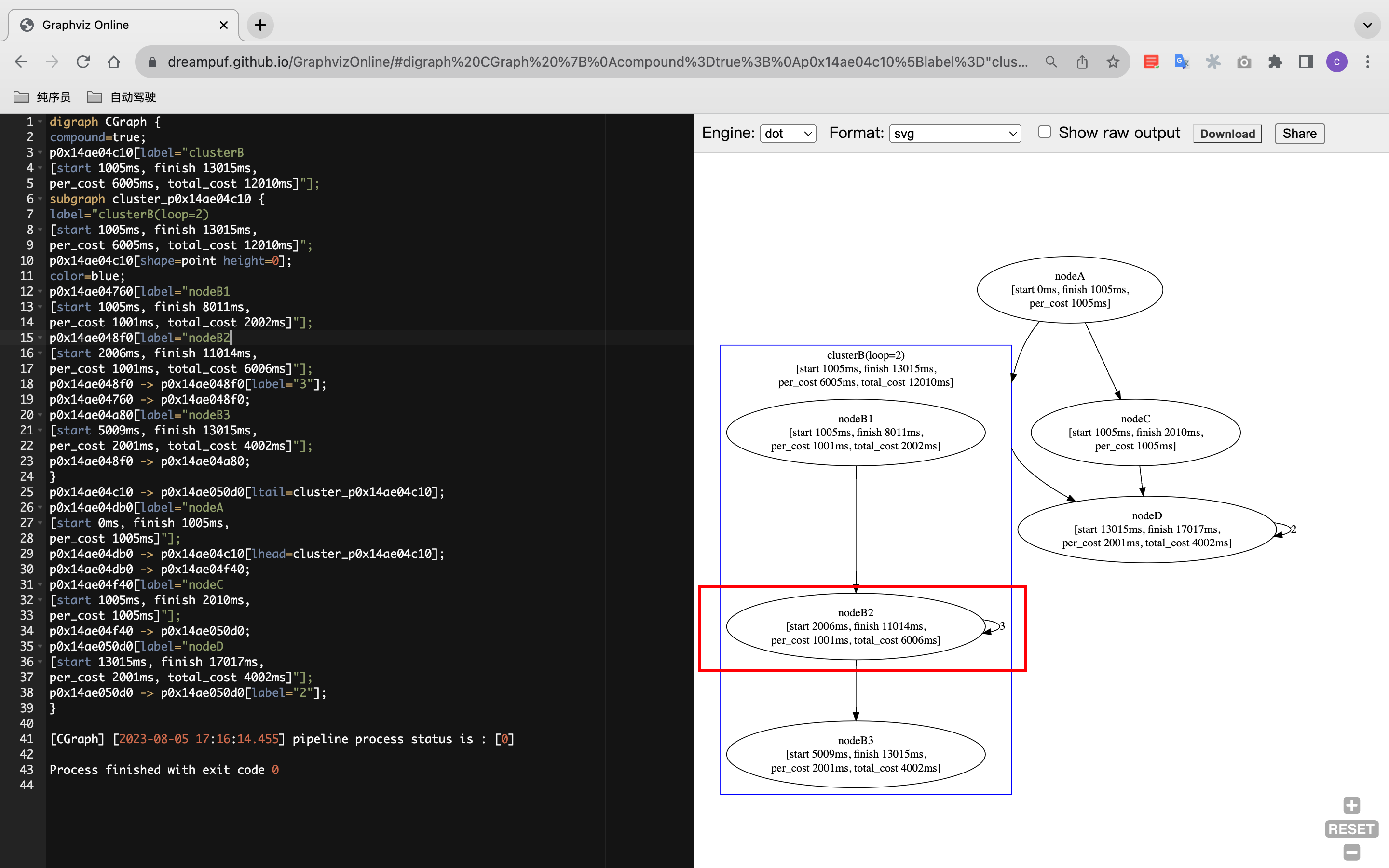
我们稍微解释一下:
- start: 开始的运行的时间(距离pipeline init 开始,单位均为 ms)
- finish: 最后一次运行的时间
- per_cost: 平均每次执行的耗时
- total_cost: 总耗时(仅单次执行的元素中,没有这一项)
因为一个node(或者group),可能会运行多次,但可能并不是连续运行,所以 finish-start的时间,并不一定等于 total_cost ,这一点需要稍微强调一下。相信有了这个工具,您可以更好的编排和优化自己的流图了,思路可以有:
- 耗时较长算子的专项优化
- 拆分较长时间的 element,设计并发逻辑
- 重新规划 element 的依赖关系或者执行顺序
等等等,我们之前就是这样干的。做的时候,记得28定律,先把耗时的大头(或者是程序员)给优化掉。
| 本章小结 |
本章小结中介绍的优化项,都是CGraph在演进过程中,各位用户反馈的真实使用意见。也是我们在开始的时候,设计不周全的点,有些内容,的确就是我自己的知识盲区。但好在,在大家的共同努力下,终于也都一一解决了。项目也是在这样的环境中,健康成长。

by the way,前阵子,我们收到了来自上海国泰君安的朋友,发来的感谢信。在此感谢贵团队的信任和帮助。支持的用户多了,但收到感谢信这个事情吧,还是第一次,哈哈
这些年,我们支持了包含AI研究、推理引擎、互联网、游戏开发、应用开发、各种行业不同公司、组织、学校的各种需求,积累了丰富的落地经验。也希望这些经验,今后可以落地在自己手头和身边的工作中去。
色丶图也会不断的迭代,往更简单、更好用、更高效的路上,不断迭代。下面是我的个人微信,也欢迎大家随时交流,多多指教。一起为项目贡献自己的智慧。

[2023.08.05 by Chunel]
推荐阅读
- 纯序员给你介绍图化框架的简单实现——执行逻辑
- 纯序员给你介绍图化框架的简单实现——循环逻辑
- 纯序员给你介绍图化框架的简单实现——参数传递
- 纯序员给你介绍图化框架的简单实现——条件判断
- 纯序员给你介绍图化框架的简单实现——面向切面
- 纯序员给你介绍图化框架的简单实现——函数注入
- 纯序员给你介绍图化框架的简单实现——消息机制
- 纯序员给你介绍图化框架的简单实现——事件触发
- 纯序员给你介绍图化框架的简单实现——线程池优化(一)
- 纯序员给你介绍图化框架的简单实现——线程池优化(二)
- 纯序员给你介绍图化框架的简单实现——线程池优化(三)
- 纯序员给你介绍图化框架的简单实现——线程池优化(四)
- 纯序员给你介绍图化框架的简单实现——线程池优化(五)
- 纯序员给你介绍图化框架的简单实现——线程池优化(六)
- 纯序员给你介绍图化框架的简单实现——距离计算
- CGraph 主打歌——《听码农的话》
- 聊聊我写CGraph的这一年
- 从零开始主导一款收录于awesome-cpp的项目,是一种怎样的体验?
- 炸裂!CGraph性能全面超越taskflow之后,作者却说他更想…
- 以图优图:CGraph中计算dag最大并发度思路总结
- 【B站视频】CGraph 入门篇
- 【B站视频】CGraph 功能篇
个人信息
微信: ChunelFeng
邮箱: chunel@foxmail.com
个人网站:www.chunel.cn
github地址: https://github.com/ChunelFeng
