大家好,我是不会写代码的纯序员。今天,想跟大家聊一下,在CGraph框架中,是如何进行参数的传递。在讲之前,需要强调一下:这只是我个人能想到的比较合适和好用的方法。如果大家有什么好的方案或者值得优化的点,也欢迎随时提意见。
首先,还是照例,先上源码链接:CGraph源码链接
| 功能介绍 |
参数传递,大家都不陌生,int add(int a, int b),谁还不是个接口调用大师呢。dag流图中的依赖执行,也可以分为几种不同的形式:比如 算子级别的依赖(a、b算子执行完了之后,才能执行x算子),再比如 参数级别的依赖(p、q参数被赋值了之后,才能执行x算子)。这其中,都涉及到了参数的传递。
a算子和b算子,分别实现自己的功能,等待框架调度执行的同时,还能做到参数有效互通。这需要合理的解决以下几个问题:
1,如何使用统一语义,满足各种不同参数的传递(多)
2,如何实现参数快速的传递(快)
3,如何确保参数传递的准确,做到彼此互不干扰又信息互通(好)
4,如何保证易用性,降低出错风险和排错成本(省)
接下来,我们主要围着多、快、好、省这几个点(jd请打钱),结合代码来讲解一下实现流程。

| 多 |
首先,一个图框架中,可能有任意多个参数,也可能有任意多组参数。我们尽可能使用统一语义,来承载所有可能发生的情况。
我们之前提过,每个自己实现的算子,都继承了GNode类。也就是说,都有属于自己的三个函数,init(),deinit()和run()。其中,init和deinit均为单次执行,run可以多次循环执行。这样的设计,可以在算子init的函数中,生成一个参数,然后在run(或者其他算子的run方法)中使用。
我们看例子:
/* 定义一个参数,继承自GParam类 */
struct MyParam : public GParam {
void reset() override {
iValue = 0;
}
int iValue { 0 };
int iCount { 0 };
};
/* 实现一个写算子 */
class MyWriteParamNode : public GNode {
public:
CSTATUS init () {
CSTATUS status = STATUS_OK;
// 定义一个名为"param1"的MyParam类型的参数
status = this->createGParam<MyParam>("param1");
return status;
}
CSTATUS run () {
MyParam* myParam = this->getGParam<MyParam>("param1");
if (nullptr == myParam) {
return STATUS_ERR;
}
int val = 0;
int cnt = 0;
{
CGRAPH_PARAM_WRITE_CODE_BLOCK(myParam)
val = ++myParam->iValue; // 对param中的信息,进行写入
cnt = ++myParam->iCount;
}
return STATUS_OK;
}
};
/* 实现一个读算子 */
class MyReadParamNode : public GNode {
public:
CSTATUS run () {
MyParam* myParam = this->getGParam<MyParam>("param1");
if (nullptr == myParam) {
return STATUS_ERR;
}
int val = 0;
{
CGRAPH_PARAM_READ_CODE_BLOCK(myParam)
val = myParam->iValue;
}
return STATUS_OK;
}
};
这段代码,首先定义了MyParam这个类型的参数,其中又包含了iValue和iCount这两个参数。当然,你可以在其中定义任意多个参数,也可以定义任意多个类似MyParam的参数集合。
使用的时候,通过类型(例:MyParam)和名称(例:"param1"),就可以在这个pipeline中的任意算子里,获取和修改这个参数的内容。
| 快 |
快,在一般的情况下,都属于褒义词。
为了实现在dag中参数的快速传递,我们使用的是在pipeline中通过unordered_map<string, GParam *>进行传递。createGParam就是向unordered_map中插入一个节点,getGParam就是通过key去获取这个节点的信息。unordered_map底层是hash表,可以实现理论O(1)的查询速度,已经是快的极限了。
值得一提的是,在参数创建的时候,是在框架内部隐式加锁的。但是在读取参数的时候,是没有加隐式处理的——具体看下面一部分哦。
| 好 |
提到【好】,其实有很多维度的指标。我这里主要说一下我在做决定之前的一些推敲,水平有限,很欢迎大家多提意见。
创建和获取逻辑分离
设计的时候,考虑的是在算子的任意地方,都可以create和get任意参数的。我很推荐在init的时候,把需要创建的参数都创建一遍。确保多次执行run方法的时候,不需要反复执行创建函数了。
多线程互斥
就拿下面的图来说,b和c是并发执行的。如果b和c同时get一个参数,就存在多线程竞争问题。特别是当b和c同时对一个参数进行修改的时候,如果不做好保护,就可能会出现异常现象。
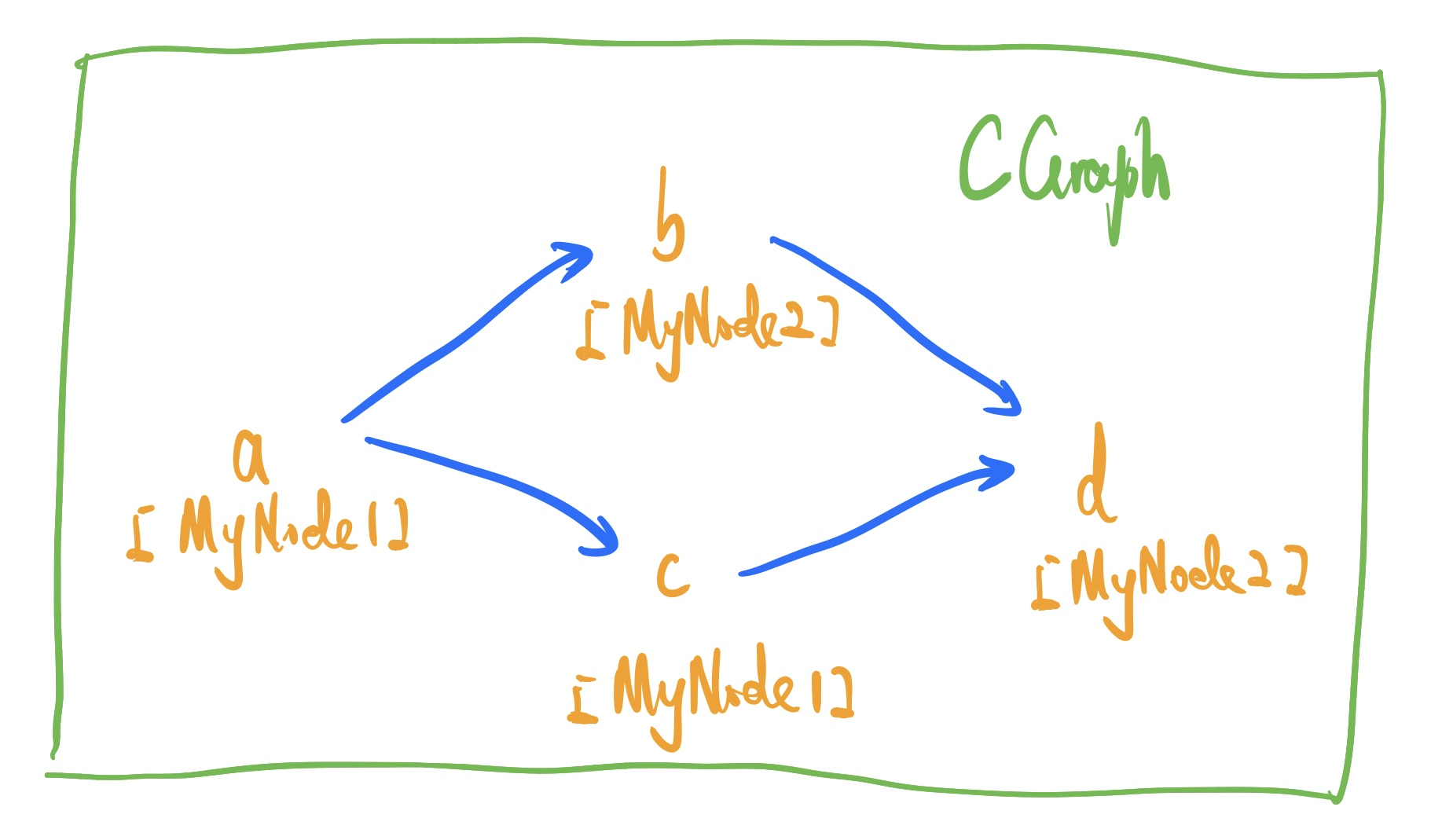
为了避免这种情况,我们提供了两个语义:
CGRAPH_PARAM_READ_CODE_BLOCK(myParam)
CGRAPH_PARAM_WRITE_CODE_BLOCK(myParam)
来标识参数进入读区域或者写区域。在需要改动参数的位置,加WRITE的代码块,在仅读的时候加READ代码块。
当然了,我们并不推荐您这样设计流图和参数。一个参数在a中写值,b中读值,d中写值(即在非并行算子内,读或写),是不需要进行任何加锁限制的。我们之所以提供各种任意多种类的参数组合,也就是为了能够方便更好更合理的安排流图中参数的传递。
在设计初期,我也曾考虑过通过类似java中ConcurrentHashMap这种结构来实现线程安全。但是考虑到,在图中创建参数是少见操作,而不互斥的获取、修改参数是常见操作。如果一刀切的使用ConcurrentHashMap中的分段锁结构来确保线程安全,可能会使得每次get操作,都变成有锁的了。而现在这种做法,一个优势就在于,可以上最细粒度的锁——代价就是需要人为操作一下了。不过好像也没啥难的哈。
参数复位处理
有些参数是需要随着pipeline执行一次结束的,有些参数是随着pipeline的执行持续累加的。
就拿上面代码的例子来说吧,我想用iValue的值,来计算当前pipeline中有多少个算子,而使用iCount来记录pipeline被执行了多少次。这就需要在每次pipeline执行结束的时候,对iValue值重新赋0,却保留iCount的值。
为此,我们在GParam中提供了reset()接口,其子类必须实现该方法。pipeline中所有的param,会在当次pipeline执行完成后,调用reset方法。看上面那个例子,在每次pipeline执行完成后,iValue值会清0;而iCount的值,会被带到pipeline的下一次执行中去。
| 省 |
用一个框架,省事的最大表现一个是上手简单,还有一个就是问题快速定位。
在CGraph中创建参数,获取参数一共只有两个方法。createGParam函数,返回值0表示创建成功,其他表示失败。getGParam函数,获取成功返回对应的param指针,失败直接返回nullptr。这都没啥好说的。
简单讲一讲几种可能造成失败的情况吧,一个就是参数重复创建,还有一个就是get参数的key和类型对不上,或者就是根本没这个key。这些点,都可以从函数的返回值上很明显的看出。
| 结束语 |
这一章,主要介绍了CGraph中,如何在图化框架的各个算子中,实现参数的传递。当然了,有些支持分布式的图化框架可能还会涉及到跨进程/跨机器/跨区域的参数传递。这又是另外的问题了,而且难度一步一步的呈指数级增加。这不在我们接下来的讨论范围之中,不过很希望懂的朋友可以指教一下。兴许今后我们也做成分布式的,也说不定哈。
下一章,我们会跟大家介绍一下CGraph中的条件执行(condition)模块——这个模块有一部分功能,需要依赖参数模块。到时候,大家可能会更加了解为什么要这样设计param这部分了哦。
累了,纯序员跟大家说晚安了~~~
[2021.07.18 by Chunel]
个人信息
微信: ChunelFeng
邮箱: chunel@foxmail.com
个人网站:www.chunel.cn
github地址: https://github.com/ChunelFeng