大家好,我是不会写代码却忽然想转行写算法的纯序员——Chunel Feng。最近,互联网人的日子着实不好过。大家每天都喊着节能减排,总有种【程序和程序员之间,必须有一个被优化】的感觉。
为了避免今后无砖可搬的困境,今天我想站在一个业余爱好者的角度,跟大家来聊一些关于ANNS(Approximate Nearest Neighbor Search)算法,也就是通常意义上说的向量检索算法的一些优化思路。
首先申明,我并非专业领域的人员,我指的不是 我并非ANNS领域的专业人员,我指的是,我不是什么专业的程序员。在这里,描述的更多的是我参考一些文献,和请教行业大佬而获取的知识,并且加以思考(mark)和转述(ctrl+cv)。内容和思路相对比较通用,以ANNS算法作为切入点,其他领域的童鞋也可参考相关思路。
阅读这篇文章的前置条件,是您对向量检索概念和hnsw算法过程有一些了解。推荐一篇博文入门:一文看懂HNSW算法理论的来龙去脉 。如果您不了解相关背景,也不愿看入门博客,那也推荐您继续看下去,因为文中,还有一些段子。
| 背景 |
不知是否众所周知,现在ANNS算法通常分为四个派别:图(多图)思路,量化/降维思路,哈希思路,树(森林)思路。近些年,图思路由于较高的召回率、较好的性能和较多的后期优化思路,脱颖而出,hnsw就算是其中的代表作。
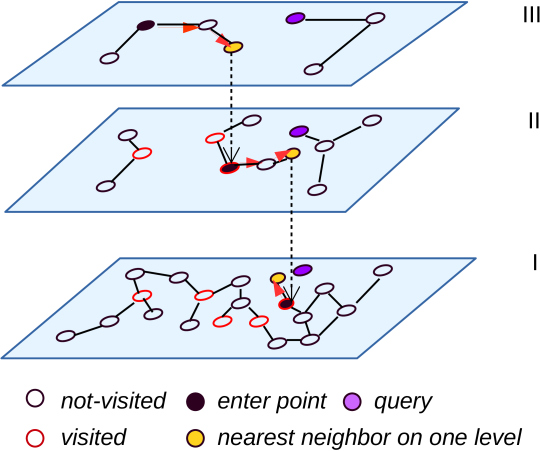
hnsw有两个优势:一个是通过平层图+跳表的思路,加速了开始阶段远距离导航的过程;一个是通过启发式选边的思路,降低了候选集局部密集的干扰。现有的很多算法研究思路,都是基于这个方案,做进一步针对性的优化。
接下来,我就针对我了解到的一些优化方案,一一讨论和分享。主要包括:分而治之,主次分明,前世今生,合纵连横。
| 分而治之 |
当前的图模型算法有很多,比如 nsg,vamana,hnsw等。其中,选入口点、导航、裁边等过程,思路各有不同。但是,如果加以总结、分析和抽象,会发现基本所有的图算法,都有以下思路:
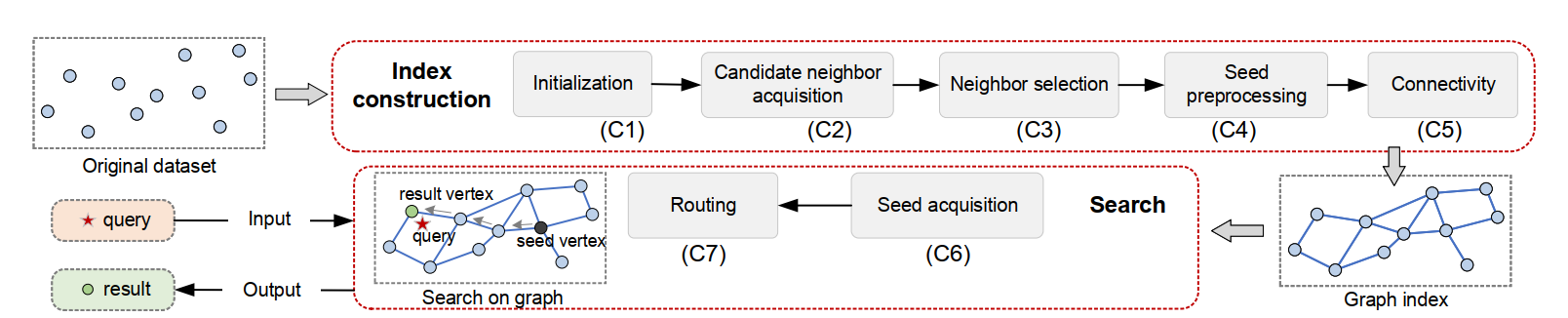
构图的时候
- 初始化连通图(初始化)
- 为连通图选择邻居(连边)
- 对邻居进行优选(选边+裁边)
- 选定一个图(或 多层图)的入口点
- 确保图的联通性(避免出现孤岛)
查询的时候
- 从入口点进入图
- 图中导航,搜索到topK个最近邻居
以上是现有的大佬的总结方法。你也可以有自己的分法,或者自行扩展。但更需要应对的问题是,分好 元素(component)了之后,怎么办。
首先,可以将各种算法不同component阶段的优质思路 拼凑起来,形成一套完成的 构图+查询 的流程。那我们可以认为,这个组合算法(缝合怪)其实就集合了当前所有图算法优势。
然后,我们在针对特定的数据集,将这个缝合怪的特定component,进行针对性的优化。那就可以认为,得到了一套适配当前数据集、并且集合了众多图算法优点 的算法。
同样的思路,也被用于图像算法性能调优上,并且快速取得了较好的成果:图像、神经网络优化利器:了解Halide ,有兴趣的朋友可以参考一下。
| 主次分明 |
在做性能优化的时候,我们理应考虑轻重缓急,抓大放小。打个比方,你从杭州想坐火车去上海找童鞋玩,那肯定是先坐火车,从杭州火车站到上海火车站;然后再做公交车,到你朋友家的小区门口;最后从小区门口挨家挨户的走到他家门口。如果你朋友在上海买不起房子的话,约在他公司附近的星巴克,也是同样的道理,嘿嘿。
在这个过程中,坐火车的那一段,相当于是粗导航(Navigable),只要确保大体方向对,几站路就能到上海火车站。
坐公车那一段,相当于是细粒度查询。这里就要开始小心了,如果做错公车,或者是坐过了车站,那会导致你下车后要走很长的路,甚至最后没法找到朋友家。
到了小区门口之后,挨家挨户找的那个过程,其实就像是在少量候选集中,进行暴力搜索。一定要找到对的门牌号为止。
最后,带着笑脸,低头寒暄,说一句,好久不见。
又或者,装作若无其事的样子,说一句,好巧,原来你也在这里。
找到之后做点什么,那就不是我们研究的流程了,在这里不加以赘述。
同样的,ANNS算法在查询过程中,刚开始查询得到的候选点,和快结束时查询得到的候选点,虽然邻居数量大体相同,但对最终的召回率(或准确率)的影响,是不同的。
在刚开始查询的阶段,只要保证大致是沿着正确的方向导航即可——这样可以,减少比对(计算)次数,从而缩短查询耗时。在候选点和查询点非常接近的时候,再使用近乎暴力的方式查询——这样可以提高准确率。
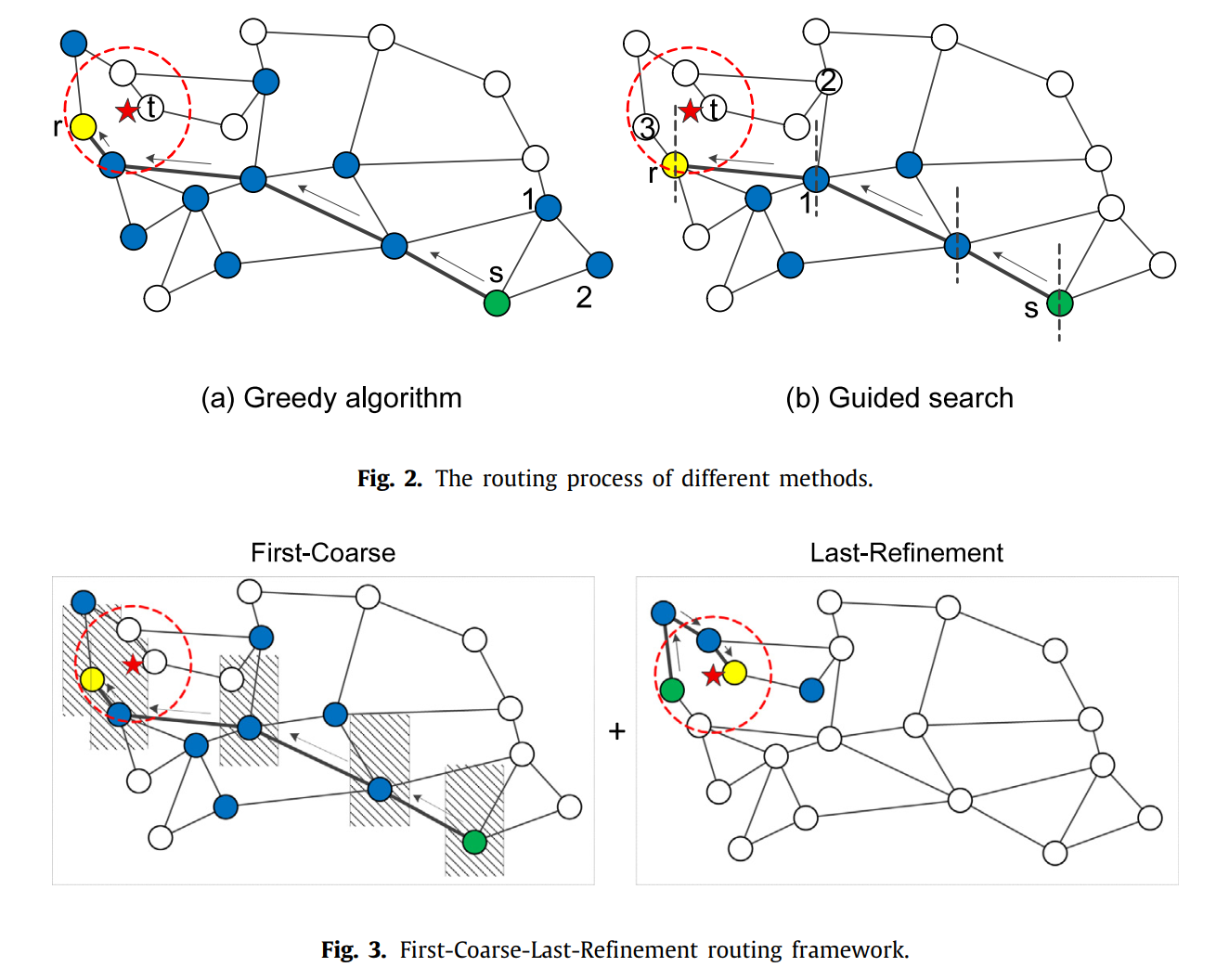
图看不懂就算了,不要在意这些细节,我也是直接从论文里截图过来的。大概意思就是我举的那个例子:红色五角星表示你朋友家(query点),绿色点表示杭州火车站(入口点)。阴影部分可以想成是坐火车+公车的过程,红圈里面可以想成是挨家挨户的找的过程。
| 前世今生 |
以上内容,我们关注的是算法构图和查询的流程,都focus在ANNS算法本身。这个时候,如果我们把格局打开,考虑一下算法建模之前呢?考虑一下,模型训完之后呢?
前世
ANNS算法构图的dataset,是海量的高维向量。而dataset是通过其他embedding算法计算出来的,分布会随着原材料的不同,呈现一定的随机性和区域性的。这将引发一些不确定性和局部热点问题。
设想,如果我们在构图之前,对dataset做一个预处理,或者进行一些定向分析,那是不是也可能提升最终构图的质量。
预处理也有一些思路,比如pca、pq等方式,可以降低向量的维度,从而降低计算工作量。或者,对dataset进行空间转换,使得数据分布尽可能均匀,降低理论平均查询耗时。再或者,做二次embedding,尽可能的缩短真的相近向量的距离。
今生
模型创建完之后,当然就可以直接用于query点的快速查询了。不过,这就万事大吉了么?那除了程序员之外,还能有啥可以优化的空间么?

当然可以。比如我们可以尝试结合一批真实的query请求,分析一下,query点的分布,从而调整图模型的入口点,使得模型本身和实际使用情况更加match。
再或者,我们可以根据这些query的导航路径,来查看哪些边在实际查询中,基本没用到;哪些边更经常被访问;哪些变对最终结果影响更大,从而对现有的图模型做进一步的加权和裁边操作——让模型和程序员一起,变秃变强。
| 合纵连横 |
我们常说,一个人的成长,要考虑自身努力,也要结合时代背景。针对ANNS算法模型的优化,也是如此。我们不仅要把焦点放在图算法本身,还需要考虑周边因素的一些影响。
合纵
我们说了很多图算法相关的内容和优化,也在最开始的时候,提到了ANNS算法,大体有四种思路。很多时候,这些思路是可以进行进一步的组合,并且发挥出更大威力的。
比如,选择入口点的时候,就可以考虑通过KD-Tree,快速找到局部入口点。或者通过哈希的方法,更好的做子图的拆分。我上面提到的,将图算法进行component拆分,很可能其中的某个component,就可以照搬其他类型算法的思路。
连横
以上内容,我们貌似都是在一个特定设备上,针对模型和数据集进行优化。那我们再讨论一些与设备和运行环境相关的问题。比如,数据量太大,内存无法读取,单次查询过程需要从磁盘上反复io数据;再或者,冷数据相对较多,缓存命中率低;又或者,有单批大量计算,cpu已经冒烟。

针对这些问题,我们在设计模型的过程中,可能更需要考虑降低io开销(参考B树 vs B+树)、缓存友好、计算相对集中的结构和构图方式。从而针对特定的硬件设备、更专业的领域、和更极端的情况下,发挥出最更的威力。
| 个人总结 |
本篇文章,主要介绍了一些ANNS Graph Based算法的优化思路,旨在以现有hnsw算法为标准,进行进一步的剖析和优化,不断提升自己的认知。有一些内容,是通用思路级别的,相信对其他领域算法的研究,和其他方向的优化,也有一定的参考和借鉴意义。
很多内容,都是业内专业人士给我的指导和分享,并且被证明的确行之有效。我自己并没有做太多的实验和论证,但也参考了一些相关的博客和文档,并加入了理解和表述。希望本文对大家今后进一步的工作和研究,有参考和借鉴意义。

如果您对以上话题有兴趣,也欢迎添加我的个人微信,方便今后随时交流讨论。对了,下面还有打赏码,也期待您的打赏。讲真话,如果不是前阵子狗币跌的太多,我真的不会很在乎这一毛两毛的打赏,哈哈。
个人信息
微信: ChunelFeng
邮箱: chunel@foxmail.com
个人网站:www.chunel.cn
github地址: https://github.com/ChunelFeng

参考论文:
- A Comprehensive Survey and Experimental Comparison of Graph-Based Approximate Nearest Neighbor Search
- Two-stage routing with optimized guided search and greedy algorithm on proximity graph
- Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs
- DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node
参考博客:
参考视频资料:
对应代码实现(持续进行中):